class: center, middle, inverse, title-slide .title[ # Lecture 15: More on Databases ] .author[ ### Robin Liu ] .institute[ ### UCSB ] .date[ ### 2022-07-17 ] --- class: inverse, middle, center # Little Bit About Design --- # Database Design .pull-left[ 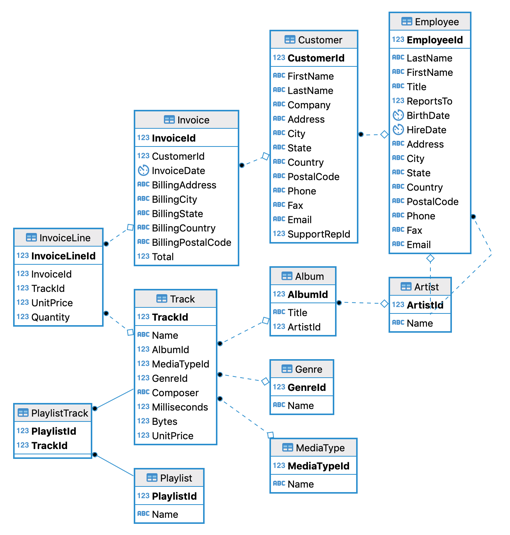 ] .pull-right[ - Tables should represent distinct real-world concepts. - Records should be uniquely identified with a primary key. - Relationships between tables represented by primary key/foreign key relations. ] --- # Database Design .pull-left[  ] .pull-right[ **Straightforward relationships** - Customer/Employee - An employee can serve multiple customers - A customer has at most one employee support rep - Track/Album - An album can contain multiple tracks - A track can be on at most one album. ] --- # Association Table .pull-left[ 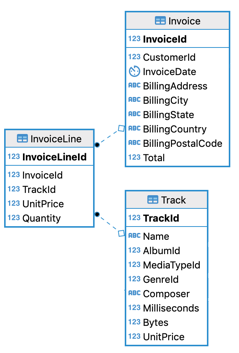 ] .pull-right[ - An invoice can contain multiple tracks (multiple tracks purchased in one transaction) - A track can be in multiple invoices (multiple people buying the same track) ] -- To represent this *many-to-many* relationship, we need the *association table* InvoiceLine. --- # Association Table ```r dbGetQuery(chinook_db, "select InvoiceLineId, InvoiceId, TrackId from InvoiceLine where trackid = 8 or invoiceid = 2") ``` ``` ## InvoiceLineId InvoiceId TrackId ## 1 4 2 8 ## 2 1155 214 8 ## 3 3 2 6 ## 4 5 2 10 ## 5 6 2 12 ``` InvoiceLine has foreign keys to Invoice and Track tables. To associate Track and Invoice, join on the association table. --- # Association Table ```r dbGetQuery(chinook_db, "select t.Name as TrackName, InvoiceLineId, i.InvoiceId, t.TrackId from Invoice i inner join InvoiceLine il on i.InvoiceId = il.InvoiceId inner join Track t on il.TrackId = t.TrackId where i.invoiceid = 2") ``` ``` ## TrackName InvoiceLineId InvoiceId TrackId ## 1 Put The Finger On You 3 2 6 ## 2 Inject The Venom 4 2 8 ## 3 Evil Walks 5 2 10 ## 4 Breaking The Rules 6 2 12 ``` ```r dbGetQuery(chinook_db, "select t.Name as TrackName, InvoiceLineId, i.InvoiceId, t.TrackId from Invoice i inner join InvoiceLine il on i.InvoiceId = il.InvoiceId inner join Track t on il.TrackId = t.TrackId where t.trackid = 8") ``` ``` ## TrackName InvoiceLineId InvoiceId TrackId ## 1 Inject The Venom 4 2 8 ## 2 Inject The Venom 1155 214 8 ``` --- # Association Table .pull-left[  ] .pull-right[ There is one more association table in Chinook. Which table is it? ] --- # Association Table Retrieve the track name and playlist names of the track with TrackId = 1. ``` ## TrackId TrackName PlaylistId ## 1 1 For Those About To Rock (We Salute You) 1 ## 2 1 For Those About To Rock (We Salute You) 8 ## 3 1 For Those About To Rock (We Salute You) 17 ## PlaylistName ## 1 Music ## 2 Music ## 3 Heavy Metal Classic ``` Retrieve the track names and playlist name of the tracks in the playlist with id = 8. ``` ## TrackId TrackName PlaylistId PlaylistName ## 1 1 For Those About To Rock (We Salute You) 8 Music ## 2 2 Balls to the Wall 8 Music ## 3 3 Fast As a Shark 8 Music ``` <div class="countdown" id="timer_62d4adb5" style="right:0;bottom:0;" data-warnwhen="0"> <code class="countdown-time"><span class="countdown-digits minutes">04</span><span class="countdown-digits colon">:</span><span class="countdown-digits seconds">00</span></code> </div> --- # Aggregation When using aggregating functions like `sum`, `avg`, `max`, `count`, ... Only select fields you are aggregating on. ```r dbGetQuery(chinook_db, "select customerid, invoiceid, invoicedate, total from Invoice i where customerid = 1") ``` ``` ## CustomerId InvoiceId InvoiceDate Total ## 1 1 98 2010-03-11 00:00:00 3.98 ## 2 1 121 2010-06-13 00:00:00 3.96 ## 3 1 143 2010-09-15 00:00:00 5.94 ## 4 1 195 2011-05-06 00:00:00 0.99 ## 5 1 316 2012-10-27 00:00:00 1.98 ## 6 1 327 2012-12-07 00:00:00 13.86 ## 7 1 382 2013-08-07 00:00:00 8.91 ``` --- # Bare Columns ```r dbGetQuery(chinook_db, "select customerid, count(*), invoiceid, invoicedate, total from Invoice i group by customerid having customerid = 1") ``` ``` ## CustomerId count(*) InvoiceId InvoiceDate Total ## 1 1 7 98 2010-03-11 00:00:00 3.98 ``` Here, InvoiceId, InvoiceDate, and Total are misleading; they are not grouped by, so arbitrary values are filled in. These are called **bare columns**. A serious SQL implementation would disallow this. SQLite designers made a mistake. [Discussion](https://stackoverflow.com/questions/67536804/are-there-in-guarantees-about-the-non-aggregated-columns-in-a-group-by-query) **Moral**: only put aggregates in the `select` line when using `group by`. --- # SQL through dplyr ```r # library(tidyverse) track_tbl <- tbl(chinook_db, "Track") track_tbl ``` ``` ## # Source: table<Track> [?? x 9] ## # Database: sqlite 3.38.5 ## # [C:\Users\zhuge\code\pstat\10\my\Chinook_Sqlite.sqlite] ## TrackId Name AlbumId MediaTypeId GenreId Composer Milliseconds Bytes ## <int> <chr> <int> <int> <int> <chr> <int> <int> ## 1 1 For Those A~ 1 1 1 Angus Y~ 343719 1.12e7 ## 2 2 Balls to th~ 2 2 1 <NA> 342562 5.51e6 ## 3 3 Fast As a S~ 3 2 1 F. Balt~ 230619 3.99e6 ## 4 4 Restless an~ 3 2 1 F. Balt~ 252051 4.33e6 ## 5 5 Princess of~ 3 2 1 Deaffy ~ 375418 6.29e6 ## 6 6 Put The Fin~ 1 1 1 Angus Y~ 205662 6.71e6 ## 7 7 Let's Get I~ 1 1 1 Angus Y~ 233926 7.64e6 ## 8 8 Inject The ~ 1 1 1 Angus Y~ 210834 6.85e6 ## 9 9 Snowballed 1 1 1 Angus Y~ 203102 6.60e6 ## 10 10 Evil Walks 1 1 1 Angus Y~ 263497 8.61e6 ## # ... with more rows, and 1 more variable: UnitPrice <dbl> ``` --- # SQL through dplyr Amazingly, we can use `dplyr` functions this object. ```r track_tbl |> filter(Bytes > 5e8) ``` ``` ## # Source: lazy query [?? x 9] ## # Database: sqlite 3.38.5 ## # [C:\Users\zhuge\code\pstat\10\my\Chinook_Sqlite.sqlite] ## TrackId Name AlbumId MediaTypeId GenreId Composer Milliseconds Bytes ## <int> <chr> <int> <int> <int> <chr> <int> <int> ## 1 2820 Occupation ~ 227 3 19 <NA> 5286953 1.05e9 ## 2 2826 Hero 227 3 18 <NA> 2713755 5.07e8 ## 3 2827 Unfinished ~ 227 3 18 <NA> 2622038 5.28e8 ## 4 2829 The Eye of ~ 227 3 18 <NA> 2618750 5.18e8 ## 5 2830 Rapture 227 3 18 <NA> 2624541 5.08e8 ## 6 2832 The Woman K~ 227 3 18 <NA> 2626376 5.53e8 ## 7 2834 Dirty Hands 227 3 18 <NA> 2627961 5.38e8 ## 8 2835 Maelstrom 227 3 18 <NA> 2622372 5.14e8 ## 9 2839 Genesis 228 3 19 <NA> 2611986 5.16e8 ## 10 2841 One Giant L~ 228 3 21 <NA> 2607649 5.22e8 ## # ... with more rows, and 1 more variable: UnitPrice <dbl> ``` --- # SQL through dplyr ```r track_tbl |> mutate(MB = Bytes / 2^20) |> filter(MB > 500) |> select(TrackId, Name, AlbumId, Milliseconds, MB) |> head(5) ``` ``` ## # Source: lazy query [?? x 5] ## # Database: sqlite 3.38.5 ## # [C:\Users\zhuge\code\pstat\10\my\Chinook_Sqlite.sqlite] ## TrackId Name AlbumId Milliseconds MB ## <int> <chr> <int> <int> <dbl> ## 1 2820 Occupation / Precipice 227 5286953 1006. ## 2 2827 Unfinished Business 227 2622038 504. ## 3 2832 The Woman King 227 2626376 527. ## 4 2834 Dirty Hands 227 2627961 513. ## 5 2842 Collision 228 2605480 502. ``` How does it do this? --- # SQL through dplyr ```r class(track_tbl) ``` ``` ## [1] "tbl_SQLiteConnection" "tbl_dbi" "tbl_sql" ## [4] "tbl_lazy" "tbl" ``` ```r class(chinook_db) ``` ``` ## [1] "SQLiteConnection" ## attr(,"package") ## [1] "RSQLite" ``` `track_tbl` is connection to the Track table in the Chinook DB on disk, just like `chinook_db`. It behaves like a tibble. --- # SQL through dplyr An aggregation example ```r track_tbl |> group_by(GenreId) |> summarize(GenreCount = n()) |> head(4) ``` ``` ## # Source: lazy query [?? x 2] ## # Database: sqlite 3.38.5 ## # [C:\Users\zhuge\code\pstat\10\my\Chinook_Sqlite.sqlite] ## GenreId GenreCount ## <int> <int> ## 1 1 1297 ## 2 2 130 ## 3 3 374 ## 4 4 332 ``` --- # SQL through dplyr ```r q <- track_tbl |> group_by(GenreId) |> summarize(GenreCount = n()) |> head(4) show_query(q) ``` ``` ## <SQL> ## SELECT `GenreId`, COUNT(*) AS `GenreCount` ## FROM `Track` ## GROUP BY `GenreId` ## LIMIT 4 ``` --- # SQL through dplyr Another aggregation example ```r track_tbl |> group_by(GenreId) |> summarize(AvgLengthMin = mean(Milliseconds) / 60000) |> head(4) ``` ``` ## Warning: Missing values are always removed in SQL. ## Use `mean(x, na.rm = TRUE)` to silence this warning ## This warning is displayed only once per session. ``` ``` ## # Source: lazy query [?? x 2] ## # Database: sqlite 3.38.5 ## # [C:\Users\zhuge\code\pstat\10\my\Chinook_Sqlite.sqlite] ## GenreId AvgLengthMin ## <int> <dbl> ## 1 1 4.73 ## 2 2 4.86 ## 3 3 5.16 ## 4 4 3.91 ``` --- # SQL through dplyr An example using `inner_join` ```r genre_tbl <- tbl(chinook_db, "Genre") track_tbl |> mutate(MB = Bytes / 2^20) |> filter(MB > 500) |> inner_join(genre_tbl, by = "GenreId") |> rename(TrackName = "Name.x", GenreName = "Name.y") |> select(TrackName, TrackId, GenreName, GenreId, MB) |> head(5) ``` ``` ## # Source: lazy query [?? x 5] ## # Database: sqlite 3.38.5 ## # [C:\Users\zhuge\code\pstat\10\my\Chinook_Sqlite.sqlite] ## TrackName TrackId GenreName GenreId MB ## <chr> <int> <chr> <int> <dbl> ## 1 Occupation / Precipice 2820 TV Shows 19 1006. ## 2 Unfinished Business 2827 Science Fiction 18 504. ## 3 The Woman King 2832 Science Fiction 18 527. ## 4 Dirty Hands 2834 Science Fiction 18 513. ## 5 Collision 2842 Drama 21 502. ``` --- # SQL through dplyr ```r q <- track_tbl |> mutate(MB = Bytes / 2^20) |> filter(MB > 500) |> inner_join(genre_tbl, by = "GenreId") |> rename(TrackName = "Name.x", GenreName = "Name.y") |> select(TrackName, TrackId, GenreName, GenreId, MB) |> head(5) show_query(q) ``` ``` ## <SQL> ## SELECT `Name.x` AS `TrackName`, `TrackId`, `Name.y` AS `GenreName`, `GenreId`, `MB` ## FROM (SELECT `TrackId`, `LHS`.`Name` AS `Name.x`, `AlbumId`, `MediaTypeId`, `LHS`.`GenreId` AS `GenreId`, `Composer`, `Milliseconds`, `Bytes`, `UnitPrice`, `MB`, `RHS`.`Name` AS `Name.y` ## FROM (SELECT * ## FROM (SELECT `TrackId`, `Name`, `AlbumId`, `MediaTypeId`, `GenreId`, `Composer`, `Milliseconds`, `Bytes`, `UnitPrice`, `Bytes` / POWER(2.0, 20.0) AS `MB` ## FROM `Track`) ## WHERE (`MB` > 500.0)) AS `LHS` ## INNER JOIN `Genre` AS `RHS` ## ON (`LHS`.`GenreId` = `RHS`.`GenreId`) ## ) ## LIMIT 5 ``` --- # SQL through dplyr `dplyr` provides a layer of *abstraction* so you don't have to write pure SQL. The data is still read from the disk! Only what we request is loaded into memory: **lazy loading**. .center[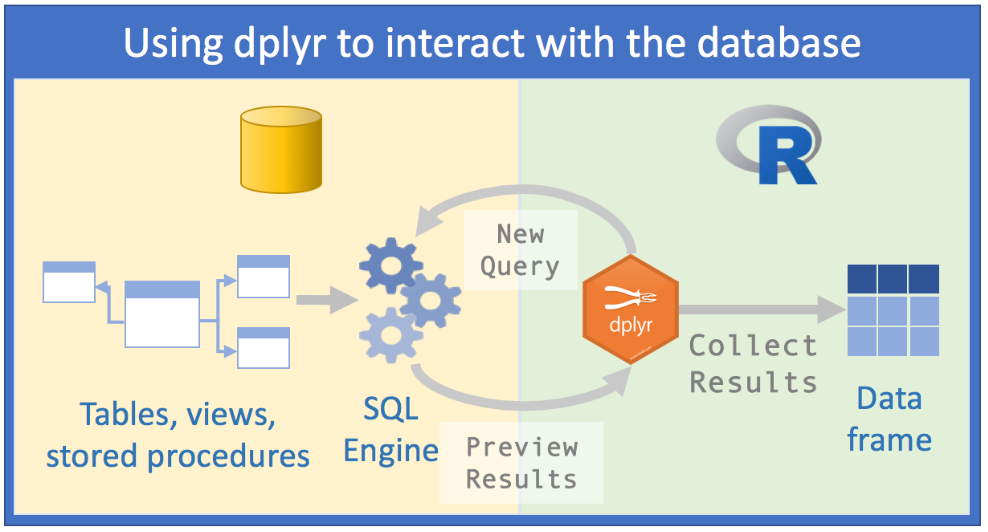] [Source](https://rviews.rstudio.com/2017/05/17/databases-using-r/) --- # Beyond the Relational Model ### Relational Model and SQL - Developed in the 1970s. - Model relationships directly via joins - Rigid schema - Preserve integrity ### Document Model and NoSQL - Developed in the 2000s to handle large volumes of web data - Data stored in *documents* instead of tables. - Focuses on *scaling* instead of integrity - Minimal support for joins --- # Data in a Relational Model .center[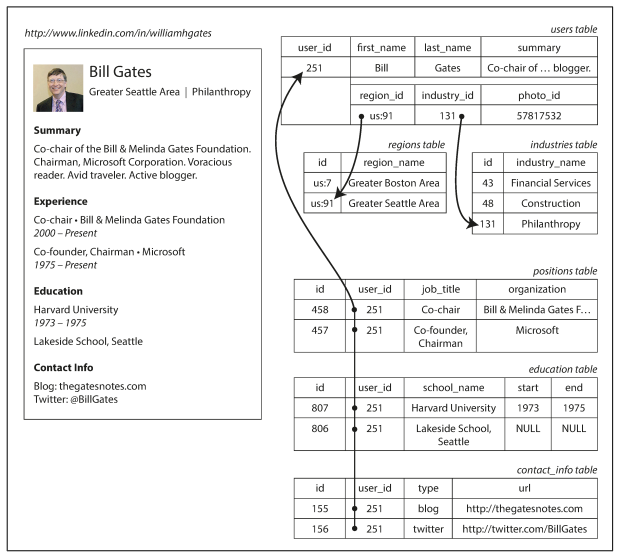] Example from [Kleppman - DDIA](https://dataintensive.net/) --- # Data in a Document Model ```json { "user_id": 251, "first_name": "Bill", "last_name": "Gates", "summary": "Co-chair of the Bill & Melinda Gates... Active blogger.", "region_id": "us:91", "industry_id": 131, "photo_url": "/p/7/000/253/05b/308dd6e.jpg", "positions": [ {"job_title": "Co-chair", "organization": "Bill & Melinda Gates Foundation"}, {"job_title": "Co-founder, Chairman", "organization": "Microsoft"} ], "education": [ {"school_name": "Harvard University", "start": 1973, "end": 1975}, {"school_name": "Lakeside School, Seattle", "start": null, "end": null} ], "contact_info": { "blog": "http://thegatesnotes.com", "twitter": "http://twitter.com/BillGates" } } ``` --- # Beyond the Relational Model - The data in a document is stored in JavaScript Object Notation (JSON). - All the data about Bill is in a single place; no need for multi-way joins. - Queries are executed directly through an abstraction layer (usually JavaScript) - Easy to scale information without altering existing tables - Basically no schema [SQL vs NoSQL Discussion](https://stackoverflow.com/questions/4160732/nosql-vs-relational-database) --- # Beyond the Relational Model 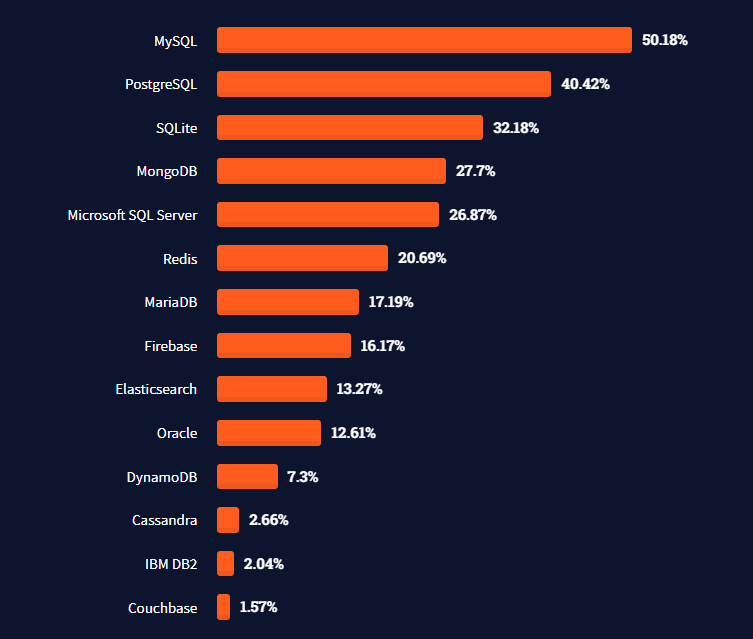 --- # Important Ideas - `dplyr` provides an *application layer* on top of SQL - `dplyr::group_by` and `dplyr::summarize` are like SQL `group by` and aggregation. -- We will become very familiar with `dplyr::group_by` and `dplyr::summarize` when we learn `ggplot2`. `filter`, `select`, `mutate`, `group_by`, and `summarize` are very powerful functions in `dplyr`.